Nötige Bandbreite für Sprachübertragung?
🇬🇧 Post is also available in English.
Heute habe ich mit scipy herumgespielt. Weil ich Lust darauf hatte (und aus anderen Gründen, die zu erklären hier zu weit führt), habe ich eine kurze Sprachaufname aufgenommen und ihr Spektrum angefertigt:
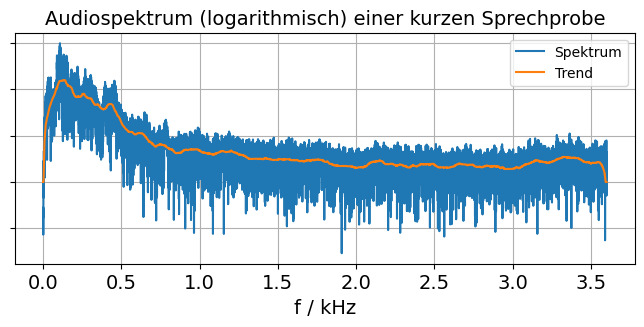
Detaillierte Bildbeschreibung, als Erklärung und um der Barrierefreiheit willen: Es handelt sich um einen x/y-Graphen. Die x-Koordinate gibt Frequenzen von 0 bis etwa 3.7 kHz. In y-Richtung sind Amplituden in einem logarithmischen Maßstab abgetragen. (Mich hat nur das grundsätzliche Aussehen interessiert, daher war ich zu bequem, herauszufinden, wie vielen dB eine y-Einheit entspricht. Deshalb ist die y-Achse nicht mit Zahlen beschriftet.) In dieses Koordinatensystem eingetragen sind zwei Graphen: Der eine ist ein recht verrauschter Graph in Blau mit den Rohdaten. Darübergelegt ist eine geglättete Version derselben Daten, als “Trend” bezeichnet. Beide fangen bei 0 Hz mit einem niedrigen Wert an, wachsen dann schnell an bis zu einem Maximum bei etwa 150 Hz. Von dort geht es stetig, fast linear abwärts bis etwa 800 Hz. Es folgt eine weiterer, fast nicht wahrnehmbarer Abstieg bis etwa 2 kHz. Ab da Richtung noch höherer Frequenzen bleibt die Spektralamplitude auf einem ungefähr konstanten, niedrigen Niveau. Am hochfrequenten Ende gibt es auf den letzten etwa 50 Hz noch einen kurzen Abstieg der Trendlinie, dem aber kein erkennbarer Abstieg der Rohdaten zugrundeliegt. Ich habe Grund zu der Vermutung, dass dies eine Art Ausreißer ist, der durch die Art der Berechnung des Trendlinie hervorgerufen wird. Mit anderen Worten: Dieser Schlussabstieg ist Quatsch und kann ignoriert werden.
Bei Betrachtung dieses Graphen fiel mir auf, dass er wenig Spektrum oberhalb von 1 kHz aufzeigt. Im Lernstoff für die Amateurfunkprüfung heisst es, dass fürs Fernsprechen die Frequenzen von 300 - 2700 Hz benötigt werden. Dieses Spektrum scheint dem insofern zu widersprechen, als es in diesem Fall auch mit weniger hohen Audiofrequenzen gehen müsste.
Das lässt sich ausprobieren! Dafür habe ein paar Tiefpassfilter gezimmert und auf die Aufnahme losgelassen.
Die entsprechend gefilterten Aufnahmen stehen hier zur Verfügung:
- Tiefpass-gefiltert mit 1000 Hz Grenzfrequenz:
- Tiefpass-gefiltert mit 1500 Hz Grenzfrequenz:
- Tiefpass-gefiltert mit 2000 Hz Grenzfrequenz:
- Tiefpass-gefiltert mit 2500 Hz Grenzfrequenz:
- Tiefpass-gefiltert mit 2700 Hz Grenzfrequenz:
- Originalaufnahme:
Selbst die mit 1000 Hz gefilterte Variante ist durchaus noch verständlich (auch wenn sie sich nicht mehr angenehm anhört). Solange kein zusätzliches Rauschen stört, würde ich so einer Modulation immer noch eine klare “R5” verleihen.
Wie habe ich gefiltert? 🔗
Um zu filtern, habe ich die Python FLOSS scipy benutzt und dafür folgenden Code erstellt:
import numpy import scipy rate, frames = scipy.io.wavfile.read("Sprechprobe.wav") TAPS = 128 # Should be adjusted if your sample rate isn't 8000 like mine. for cutoff_frequency in [1000, 1500, 2000, 2500, 2700]: firs = scipy.signal.firwin(TAPS, cutoff_frequency, width=cutoff_frequency // 5, fs=rate) filtered_frames = scipy.signal.lfilter(firs, 1.0, frames) factor = min(-16000/min(filtered_frames), 16000/max(filtered_frames)) sound_frames = numpy.array([round(fr * factor) for fr in filtered_frames], dtype=numpy.int16) scipy.io.wavfile.write(f"Sprechprobe_lowpassfiltered_{cutoff_frequency}.wav", rate, sound_frames)
Dieser Pythoncode kann unter den Bedingungen der Lizenz CC0 1.0 Universal genutzt werden. Mit anderen Worten, er ist gemeinfrei.
Diskussionsmöglichkeit 🔗
Wer diesen Blogpost kommentieren oder diskutieren möchte und über einen Fediverse-Zugang verfügt, kann auf meinen entsprechenden Tröt antworten.